Extending web applications, the 1337 way
This article will explore the common problem of extending web applications. We will look at existing approaches, their limitations, and propose another, rather unorthodox, approach to solve the problem.
Problem at hand
Let’s imagine that we want to add a feature to an existing web application. Consider a generic case: the application could be yours, or someone else’s, and the “feature” could be a simple CSS tweak, or a serious transformation of the existing app.
What options do we have today?
Method A: change the app itself
The simplest situation is when you are the developer of the app. In this case, adding a feature is a normal development process: change the source code, release a new version, deploy, and be done with it.
It is not that straightforward, however, when it comes to 3rd-party apps. For example, you can’t simply “change the source code” of your favorite food delivery app, or a search engine.
Moreover, you could hit a wall even if the app is your own. Chances are, you are relying on a lot of 3rd-party APIs. If you embed a YouTube video, you can only do what Google implements in their API. You can add a Tweet button and set a predefined tweet message, but what if you want that button to send multiple tweets at once, and also a DM? This would require customisation on the Twitter app itself, which you can’t do with this approach.
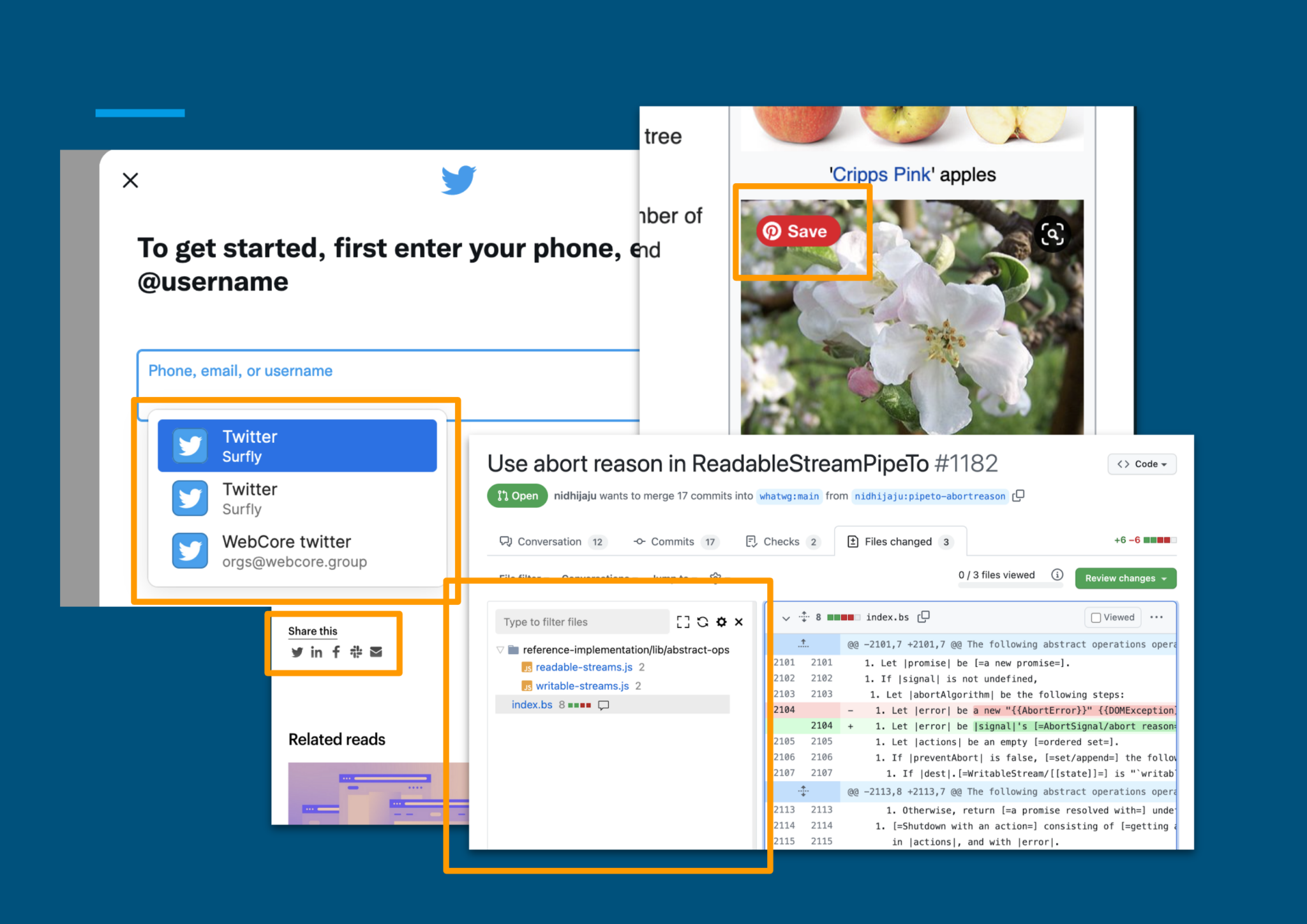
Method B: browser extensions
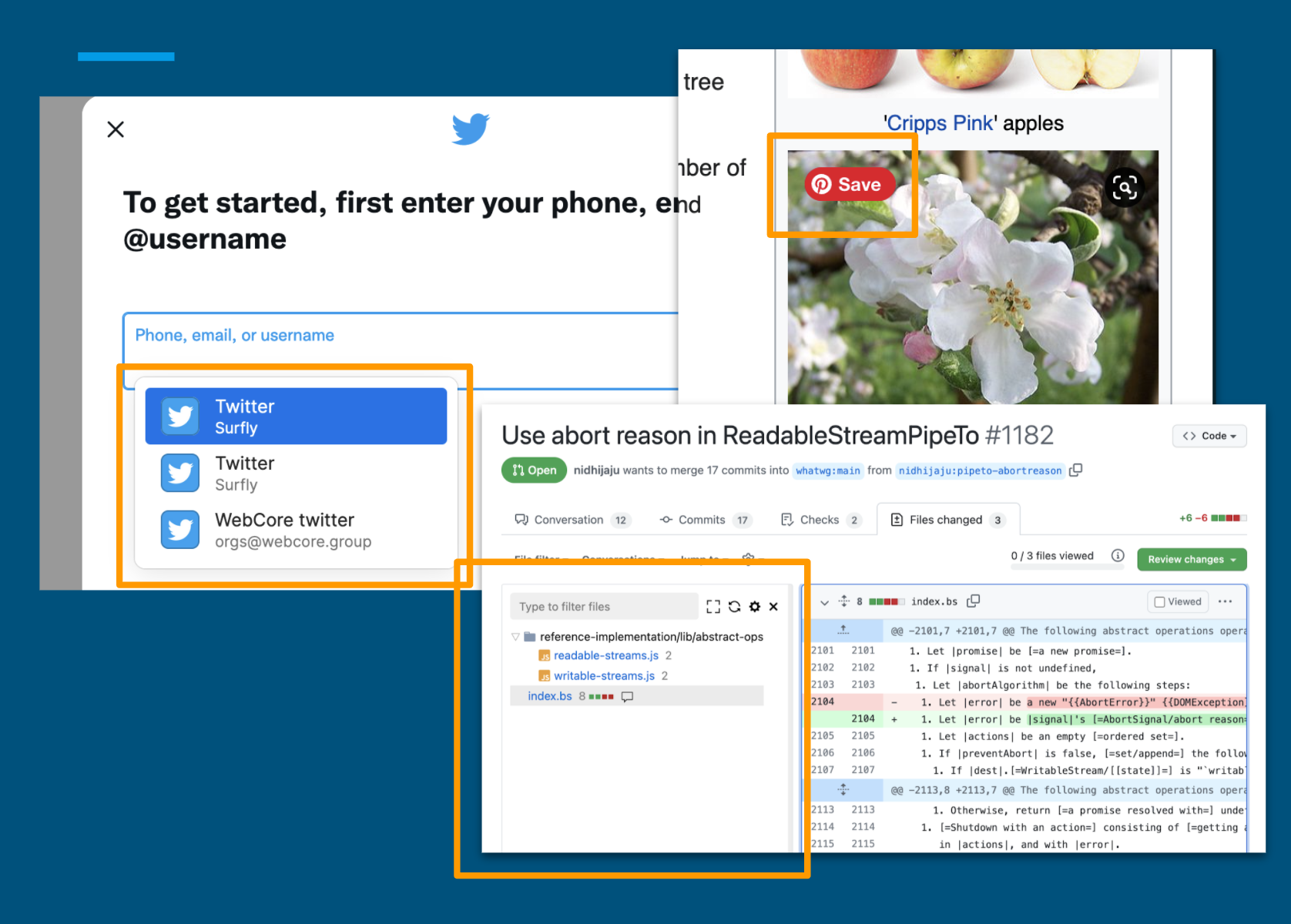
Another common way to extend websites is through browser extensions. They have (almost) full control over the browsed content and are not limited by the access to source code. The added functionality could be simple tweaks like the Pinterest button, or some more substantial interventions like a sidebar in the Github PR interface. There are still limitations though.
First, browser extensions must be installed in the user’s browser. This can be a problem for multiple reasons. First of all, not all extensions support all browsers, and it is actually quite difficult for extension developers to support all browsers. Not to mention that most mobile browsers don’t support any extensions at all.
Even if an extension is available, it is not always possible to install it. Many companies have security policies that block users from installing software on their work laptops.
Another major limitation is that users have full control of their extensions. A tech-savvy user can manipulate the extension and change the way it works. This basically rules out some use cases such as security. Imagine if you add password protection to a website using a browser extension. That’s going to be useless, because users can simply change or remove the extension and let themselves in.
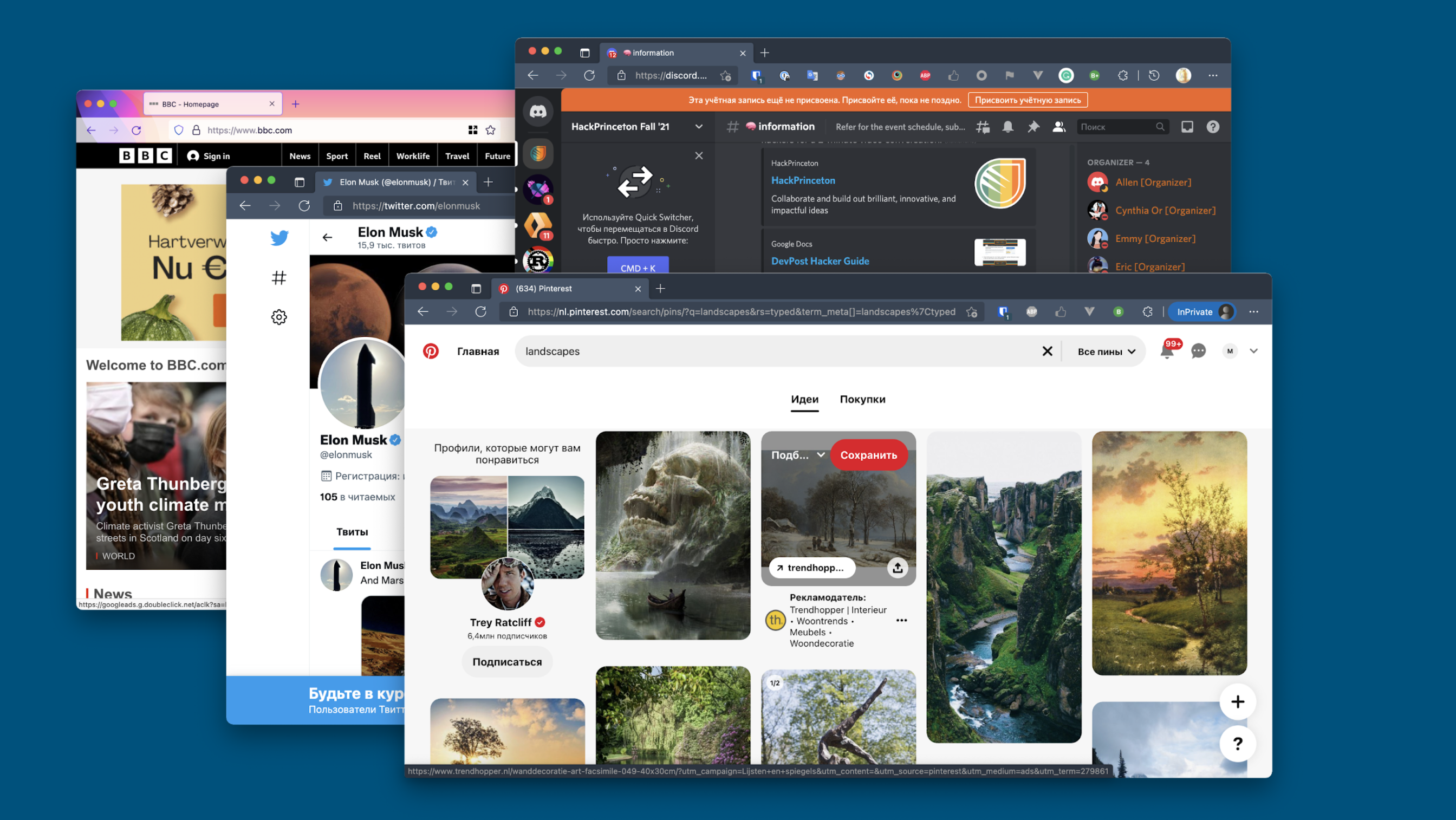
Remotely hosted browsers
A few vendors offer solutions that run a remote browser instance, and stream visual updates to the user (as low-level drawing instructions or a video stream). From the perspective of adding new features, this approach is an extension to the previous one. You can still rely on browser extensions, but they would be installed on the remote browser. This solves some of the problems with compatibility and user access mentioned above.
On the flip side, this solution has its own challenges. Because the remote browser doesn’t have a direct connection to the user’s operating system, many familiar features, such as the file upload, work differently or don’t work at all. Things that require access to hardware, such as video chat or WebUSB, will also need special workarounds and can be difficult to support. Besides, it is quite hard to scale since a fleet of browser instances requires a lot of resources.
Can we do better?
So, we have essentially two popular approaches: the server-side and the client-side. If we were to invent a new way, a cloud-based solution sounds logical, right? 🙂 Let’s see if we can “invent” it.
This is how most web applications work, in a nutshell (yes yes, it is more complicated than this, but it helps to illustrate the concept):
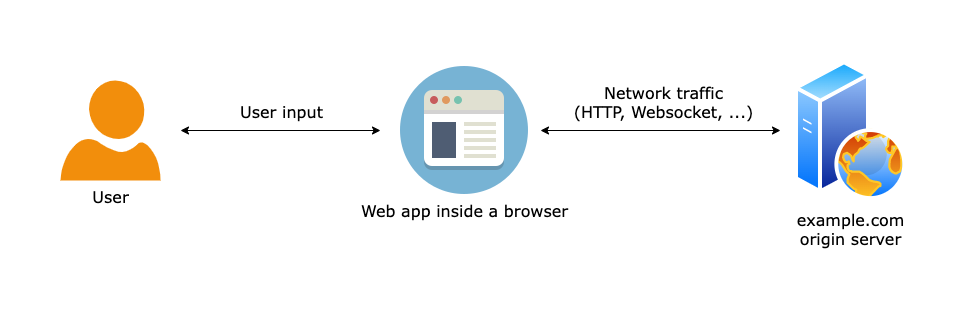
There’s generally a “server” (or a similar entity outside of the user’s computer), which sends some HTML over the network, and also some JS code that runs inside a user’s browser.
Method A changes the app itself, both the client-side and server-side implementations. Method B changes the browser, which is sitting between the server and the user’s computer, and between the user and the client-side app.
For a cloud-based solution, we need to be outside of the server and the browser. So what do we do? The first thing that comes to mind is a proxy:
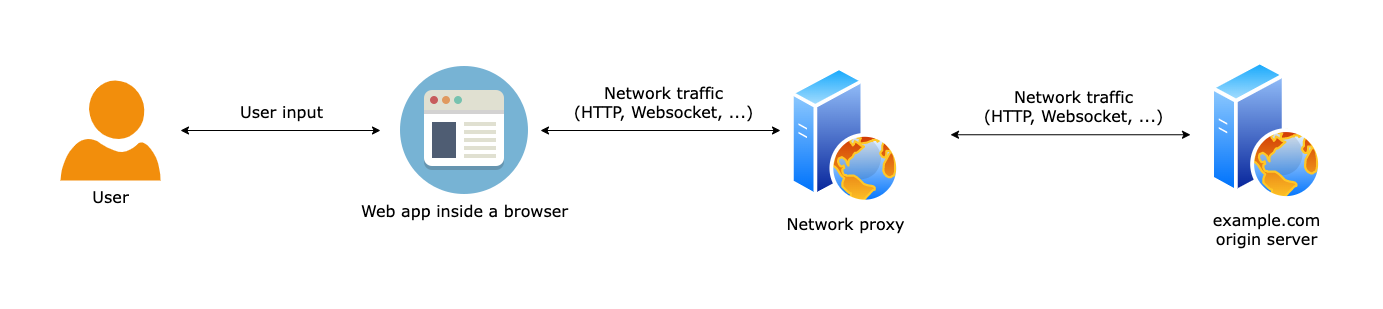
A network proxy can intercept all the traffic between the server and the browser, and modify it. This is commonly used to modify the HTML content. For example, with a simple regular expression, or substring replacement, we can change all the links on a page.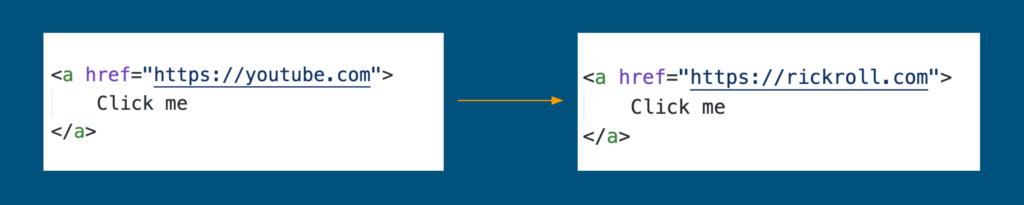
This is great, but those who have built web apps before are probably skeptical, because the content is often generated on the client side with Javascript. In this example, it would be pretty difficult to replace this link with a simple text replacement rule:

To be able to control this, we need to control the runtime inside the browser. We can do this by adding a JS sandbox environment.
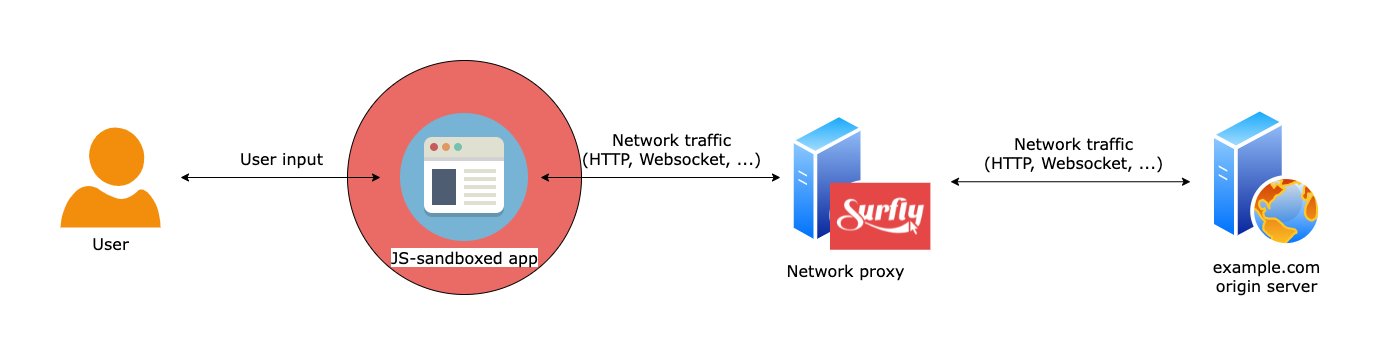
The network proxy can parse and rewrite the JS code by polyfilling global object prototypes or adding explicit wrappers in key places. These wrappers will be executed in runtime inside the user’s browser and effectively replace the logic of native JS APIs. The dynamic link setter above would look like this (note that the proxy rewrite module doesn’t need to understand the semantics of the code, it only needs to parse it and make some syntactic changes in the AST):

In simple cases like this, we can even get away with a simple global “polyfill”, so we could sandbox it without any parsing at all (note that the original source code is intact):

The same dynamic approach can be used for wrapping more tricky things like eval() and Javascript event handlers. Because the proxy sees all the traffic, it can implement additional logic both “server-side” (directly manipulating the HTTP/WS traffic), and “client-side” (by injecting JS code on the page).
Together, the client-side JS sandbox and the network proxy can intercept all inputs and outputs of a web application. As a result, you get a modified application, potentially served from a different URL, that can add any feature on top of an existing web app.
The client-side part still runs directly on the user machine, and the proxy infrastructure can be scaled horizontally. Extensions (new features) can be authored without access to source code, and without any client installation. At the same time, an extension could be developed by the original app author, by the user, OR by neither of them. Profit!
Does it work in real life?
There’s nothing more to it, really. A basic MVP of this approach could be implemented in days. But when it comes to a serious production solution, it is still a big challenge of course. The Web platform is huge and the problem surface is enormous. One of its principles is “Don’t break the Web”, which means that there are a lot of ancient mechanisms that are here to stay and need to be supported.
Nevertheless, it is possible. To showcase this approach, we launched WebToppings a few months ago. Since then, it’s gotten more and more popular every week, and now serves thousands of users every day. Check it out!
WebToppings runs a few visual examples of extra features that you can add on top of any website. Right now we are working hard to expose the underlying APIs to developers, so they can use this technology to build their own “toppings”. If you are interested, let us know!